Face Detection by MTCNN
1. 论文简介
MTCNN论文全称《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》, 2016年4月份出来的一篇人脸检测以及关键点检测的论文。该论文Code在github上公布了基于Caffe以及Matlab接口,并且只有测试部分,没有训练部分。目前github上有一些其他人复现的基于其他平台架构的,比如FaceNet中有一套基于Tensorflow的,当然也只有测试部分,训练部分需要自己改写。
2. 内容
该论文主要思想有三:
1. 将Face Detection 和 alignment作为muti-task在一个网络中同时优化,两者的相关性能够促进准确率的提高。
2. 采用了cascaded multi-task 结构,3级级联结构,每一级单独训练,对人脸以及关键点的检测由粗到细逐步的优化。
3. 采用了OHEM来提高准确率
具体的网络结构如下: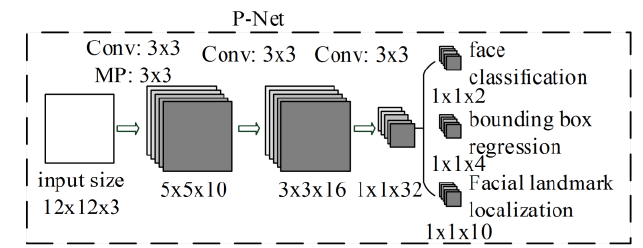
P-Net在训练的时候输入的图片大小固定12x12x3,最后输出的feature map大小刚好是1x1,再经过不同的1x1卷积来识别不同task的输出。训练的数据都是offline的预先产生,再去训练P-Net网络。具体的产生过程整体上可以说是随机crop成不同的size,然后与gt计算IOU,根据阈值分为pos,part,neg样本,并且保证三者一定的比例,其中pos和part都还有对应的offset,其中offset值有正有负。由于采用的WiderFace数据集,该数据集没有landmard信息,因此P-Net和后续的O-Net只做了classification和bounding box regression。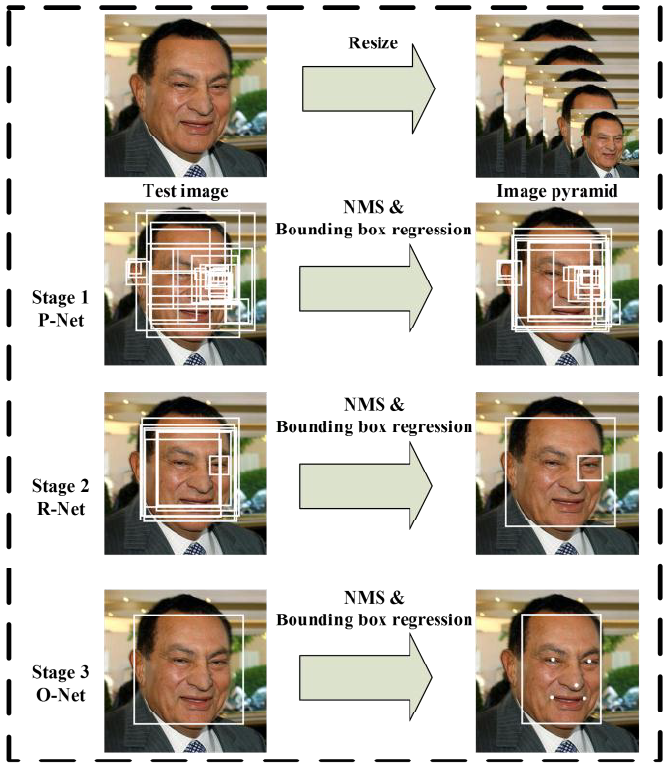
P-Net测试以及为后续R-Net准备数据,首先将WiderFace中的训练图片做不同ratio的scale,形成Image pyramid,然后将同一张图片的不同scale图片过P-Net,由于P-Net是一个FCN结构,并且输入的图片不再是12x12,因此最后输出的feature map也不会是1x1,而是NxN,类似于YOLO,SSD。针对同一个scale图片预测出来的所有box做一遍NMS,然后再针对同一张图片的不同scale预测出来的box做一篇NMS,得到该图片P-Net最终的输出结果,bounding box的offset矫正可以放在NMS之前也可以之后,这个需要具体的实践。
R-Net是在P-Net训练好的基础上,将P-Net过一遍WiderFace训练图片,得到P-Net预测的bounding box结果,与P-Net的数据预处理一样,将这些box 与 gt比较计算IOU,根据阈值分为pos,part,neg样本,并且保证三者一定的比例,其中pos和part都还有对应的offset,其中offset值有正有负。将所有的box resize到固定的24x24,训练R-Net。
R-Net测试过程与训练过程差不多,将P-Net得到的box结果resize到24x24,过R-Net做修正。
注意: 原始gt中侧脸都是采用矩形框标记,而P-Net预测出来的都是正方形的box,在计算IOU得到pos,part,neg样本时容易将侧脸框标记为neg,需要将原始的矩形框扩大成正方形框。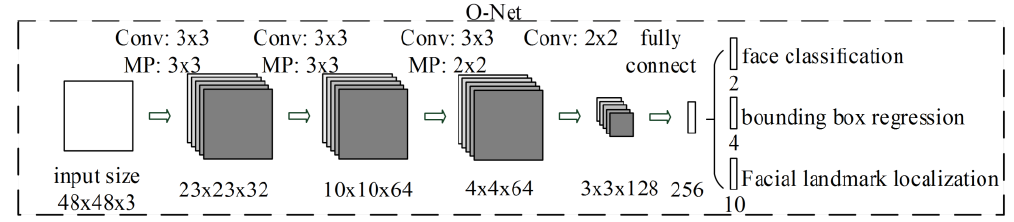
O-Net的训练以及测试过程与R-Net基本一样,唯一不同的是O-Net训练中增加了CeleA数据集的landmark进行训练,同时回归landmark点。
注意:在根据R-Net的输出结果为O-Net准备数据时可能会遇到负样本不够的情况,这时需要在原始图片中随机crop一些负样本。
